Shutting Down the PowerFlex Manager Cluster shows how to properly shut down the PowerFlex Management cluster to avoid database issues.
We have written some PowerFlex articles. Some of them are introductions to the PowerFlex solution and how to deploy a PowerFlex Manager cluster on Linux. You can click on each link below to read both articles:
https://dpcvirtualtips.com/introducing-powerflex/
https://dpcvirtualtips.com/how-to-deploy-powerflex-manager-on-linux/
Our lab environment is based on the PowerFlex 4.5.2 version:

Warning: I haven’t tested it on older PowerFlex versions. So, be careful and use it at your own risk!
First and Foremost, What is the PowerFlex Manager?
PowerFlex Manager simplifies deployment, management, and automation for PowerFlex systems. It centralizes control over computing and storage resources, streamlining lifecycle management and monitoring and configuration operations while efficiently managing and scaling PowerFlex environments.
PowerFlex Manager 4.5.2 is deployed on a three-node Kubernetes cluster. The architecture leverages Kubernetes to enhance its scalability, resilience, and ability to manage containerized services, making it more efficient in managing PowerFlex environments:
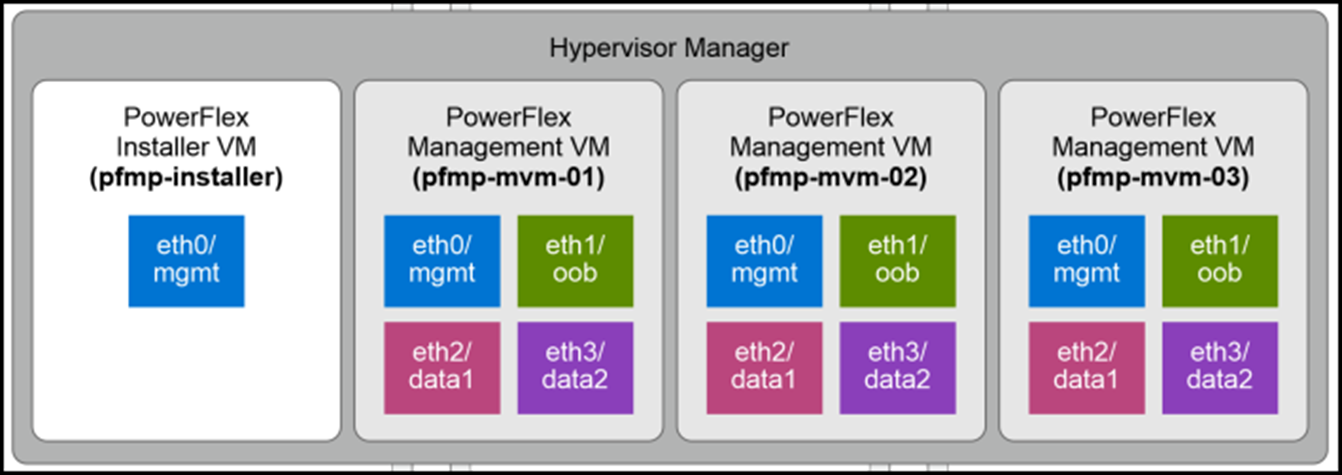
As we can see in the above picture, the management cluster is deployed using a PowerFlex Installer VM (our article “How to Deploy PowerFlex Manager on Linux” explains it in more detail. Click here to read this article).
Steps to Shut Down the PowerFlex Manager Cluster
1) Access by SSH one PowerFlex Manager node to get the node list and their status:
kubectl get nodesThe “Ready” status means that the node is working fine/usually:

2) Get the Postgres cluster status:
kubectl exec -n powerflex -c database $(kubectl get pods -n powerflex -l='postgres-operator.crunchydata.com/role=master, postgres-operator.crunchydata.com/instance-set' | grep Running | cut -d' ' -f1) -- sh -c 'patronictl list'One member is the “Leader” and the other members as “Sync Standby”:

To get the PowerFlex hostnames (this command converts the Postgres member name to the system hostname):
for x in `kubectl get pods -n powerflex | grep "postgres-ha-cmo" |awk '{print $1}'` ; do echo $x; kubectl get pods -n powerflex $x -o json | grep '"nodeName"' | cut -d ':' -f2 ; echo " "; done
3) Additionally, the following command shows all Postgres pods. Each PowerFlex Management node has one Postgres pod running on it:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
4) Shutdown PowerFlex. Access one PowerFlex Management node and execute the following commands (basically, we are shutting down the Postgres cluster to avoid corrupt data at the database level):
alias k="kubectl -n $(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo' | cut -d' ' -f1)"
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d ' ' -f1)
k patch $(k get postgrescluster -o name) --type merge --patch '{"spec" : {"shutdown" : true}}' 
5) Check that PowerFlex is shut down:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide After executing this command, all Postgres pods will be powered off correctly. Only one “pgo” pod will stay running:

Just as a curiosity, if we try to access the PowerFlex Manager UI now, it will “Not Ready” since the PowerFlex Manager database is “down”:

6) Shut down each PowerFlex Management node:
poweroffSteps to Power Up the PowerFlex Manager Cluster
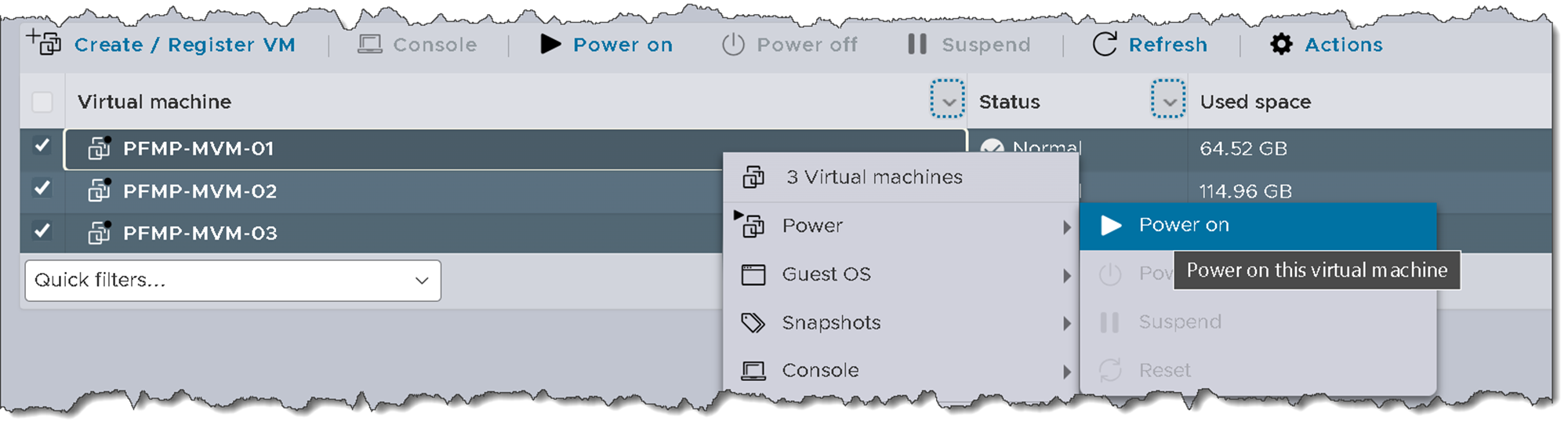
1) Power up each PowerFlex Management node (since we are in a lab environment, we are powering up each PowerFlex Manager VM):
2) Access one PowerFlex Management node to start PowerFlex (basically, we are turning on the Postgres database again):
alias k="kubectl -n $(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo' | cut -d' ' -f1)"
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1)
k patch $(k get postgrescluster -o name) --type merge --patch '{"spec" : {"shutdown": false}}'
3) Check that PowerFlex is started:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wideAfter executing this command, each Postgres pod will be started on each PowerFlex Management node:

4) Get the Postgres cluster status:
kubectl exec -n powerflex -c database $(kubectl get pods -n powerflex -l='postgres-operator.crunchydata.com/role=master, postgres-operator.crunchydata.com/instance-set' | grep Running | cut -d' ' -f1) -- sh -c 'patronictl list'One member is the “Leader,” and the other members are “Sync Standby”:

To get the PowerFlex hostnames (this command converts the Postgres member name to the system hostname):
for x in `kubectl get pods -n powerflex | grep "postgres-ha-cmo" |awk '{print $1}'` ; do echo $x; kubectl get pods -n powerflex $x -o json | grep '"nodeName"' | cut -d ':' -f2 ; echo " "; done
5) Try to access the PowewFlex Management UI. It sometimes takes a long time to be available.
Check the pods status:
kubectl get pods -AAll pods must be running. To check any pod with its status different from running:
kubectl get pods -A | grep -iv runningExample:

6) Afterward, if we try to access the Management console, we could see the message “PowerFlex Manager is initializing. Please wait”. Just wait some more minutes:

After a few minutes: