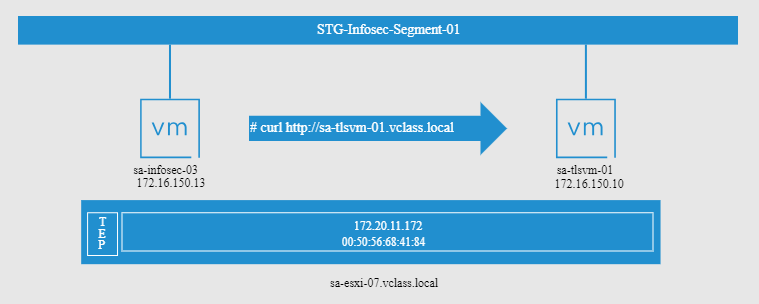
NSX Distributed Firewall Challenge Scenario shows a scenario with a connectivity issue between two VMs placed on the same segment. The challenge here is to understand the issue by using troubleshooting techniques and fix the issue.
Let’s talk a little about the scenario:
- Both VMs “sa-infosec-03” and “sa-tlsvm-01” are placed in the same Segment called “STG-Infosec-Segment-01”. In this case, both VMs are in the same broadcast domain (L2 domain);
- Both VMs are being run on the same ESXi host (sa-esxi-07.vclass.local).
What is the issue?
From the VM “sa-infosec-03” the curl command failed. The curl command is using the reach a web page provided by the “sa-tlsvm-01” VM.
Our aim here is to troubleshoot and solve the issue!
Note: There are some ways to troubleshoot this issue. So, based on this, we will show a couple of ways to identify or solve that. If you know more ways or tips, please, feel free to reach out to us and share them with us. You are more than welcome 🙂
Checking the Host Transport Node Status
Checking the host transport node status is a good idea. It’s fundamental to know if the host is prepared to be part of the NSX environment. We can access the NSX Manager UI and go to the host transport nodes session to check it:
Access the NSX Manager UI –> System –> Configuration –> Fabric –> Nodes –> under Managed by selecting the vCenter Server –> and check the status of the desired ESXi host
In this case, for instance, the host “sa-esxi-07.vclass.local” is running fine in the NSX environment:
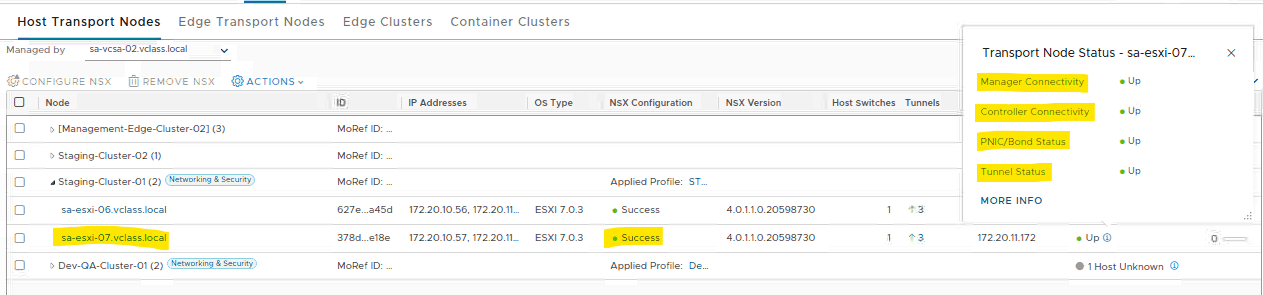
Note: If the host does not work as expected here, the first thing to do is fix this issue before going ahead.
Checking the Segment Status
As we can see in the topology scenario, both VMs are placed in the same segment “STG-Infosec-Segment-01”. We can check the segment status by accessing the following menu:
Networking –> Connectivity –> Segments –> Select the desired segment and expand it to see all the details
As we can see in the following picture, the segment is “up” (Admin state”, is connected to the Tier-0 gateway, has a default gateway assigned, and is configured OK (overall status is “Success”):
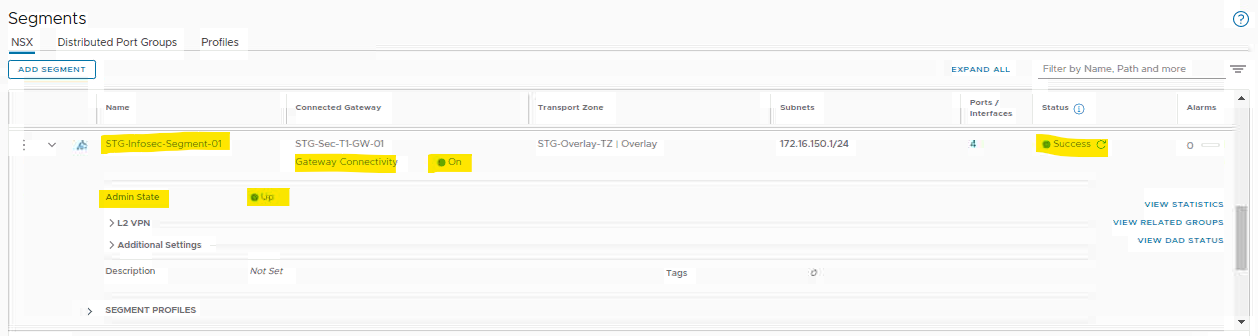
Note: If you detect some issues here, you need to fix them before going ahead.
Testing and Checking the Issue
As we told you before, from the VM “sa-infosec-03” the curl command failed. The curl command is using the reach a web page provided by the “sa-tlsvm-01” VM.
So, let’s get started and check this issue:
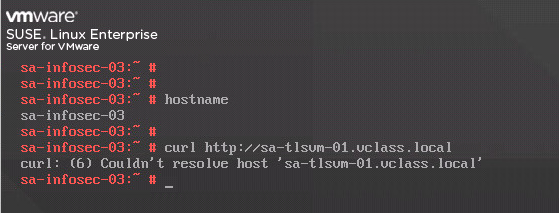
As we can see in the above picture, we have an issue probably related to the DNS because the system could not resolve the FQDN sa-tlsvm-01.vclass.local to an IP address.
1- We can start by checking what DNS server(s) our source VM is using. Because our source VM is a Linux-based system, we can check it with the following command:
cat /etc/resolv.conf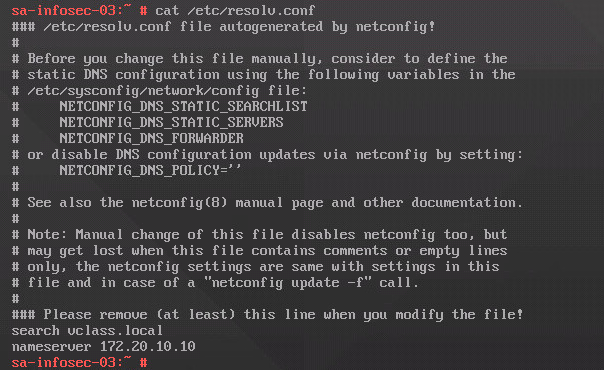
Our DNS server is 172.20.10.10. So, we can conclude that our DNS is placed external to our local NSX segment.
2- From the source VM, we can apply the traceroute command and see what are the details that this command can show us:
traceroute 172.20.10.10
We have an interesting output. Even though the “temporary failure in name resolution” message, we have an “H!”. This can indicate some route or firewall issues, but we need to investigate a little more to conclude it.
Executing the Traceflow Tool
Here, we will execute the traceflow troubleshooting tool just to see what happens with the DNS traffic from the source VM to the destination DNS server.
Access the NSX Manager UI –> Plan & Troubleshoot –> Troubleshooting tools –> Traffic Analysis –> Under Traceflow, click on Get Started:
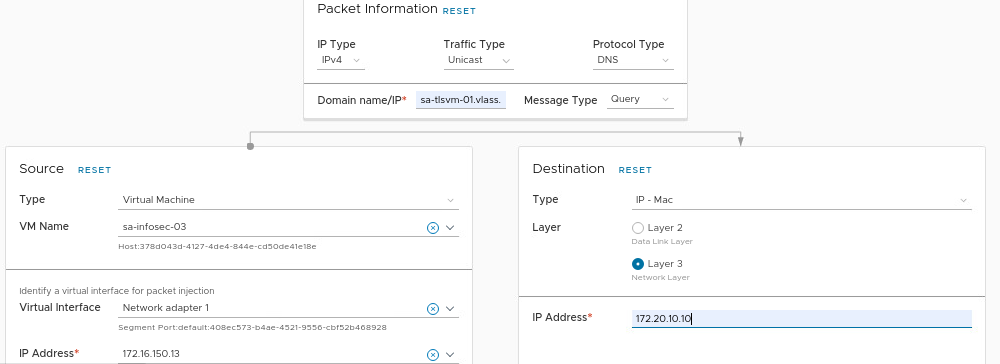
We need to configure the traceflow as we can see in the following picture:
- Protocol type = DNS
- Domain name/IP = sa-tlsvm-01.vclass.local
- Source = VM sa-infosec-03
- Destination = DNS server IP 172.20.10.10
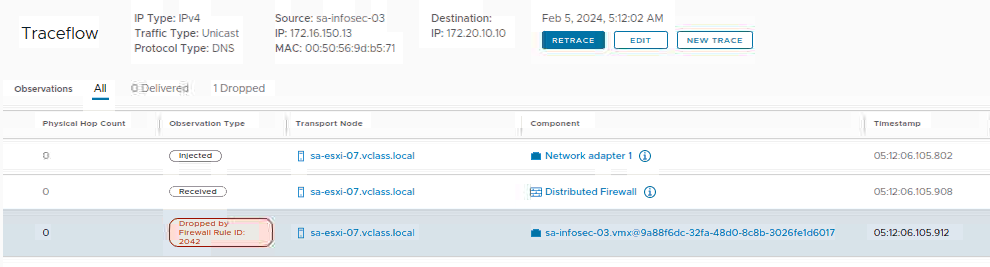
After that, click on TRACE to start the packet injection. After some seconds, we will see the results.
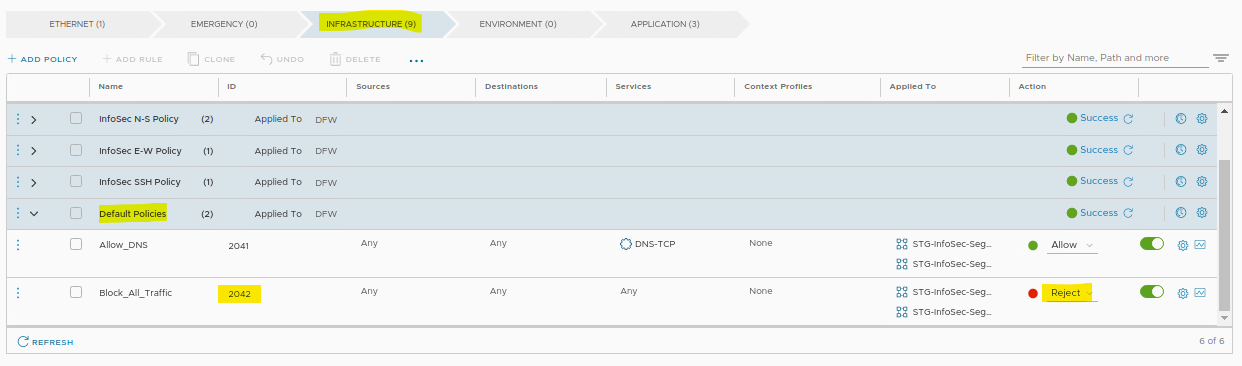
In this case, for instance, our flow has been blocked by the rule ID 2042. Sounds good, because now we have the information of what is happening with our DNS traffic:
Checking the Distributed Firewall Rule ID Details
Access the following menu to check all the details of the distributed firewall rule:
Security –> Policy Management –> Distributed Firewall –> Under Category Specific Rules, select INFRASTRUCTURE
As we can see in the following picture, rule ID 2042 has the name “Block_All_Traffic” and its action is “Reject”.
So, based on this, we can conclude that we do not have a rule to allow the DNS traffic from the source VM to the DNS server 172.20.10.10:
How we can fix this issue?
1- We can create a new rule before the rule “Block_All_Traffic” allowing the DNS-UDP traffic;
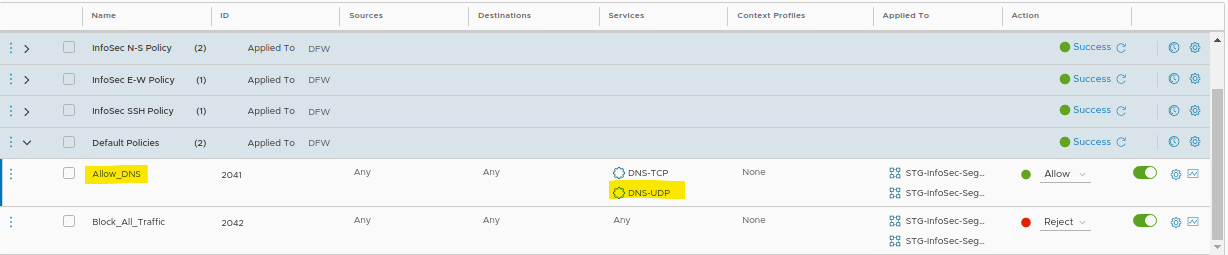
2- Or we can adjust the rule “Allow_DNS” by adding the DNS-UDP service (this rule allows the DNS-TCP traffic only). The client DNS requests are realized by using the DNS with UDP. So, we will adjust this rule by adding this service (do not forget to publish the changes after that):
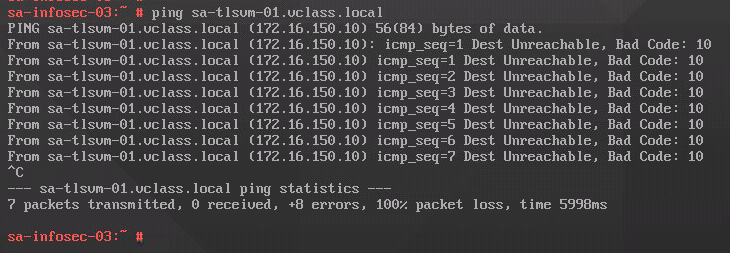
Now, from the source VM, we have a different error:

The “ping” command shows that the DNS resolution issue has been fixed, but we do not have a connection with the target VM yet:
If we execute a new traceflow (now using the TCP traceflow), we continue to see that the traffic continues blocked by the rule ID 2042.
Look that we are using the Destination port 80, and the source and destination VMs are our VMs from the challenge scenario:
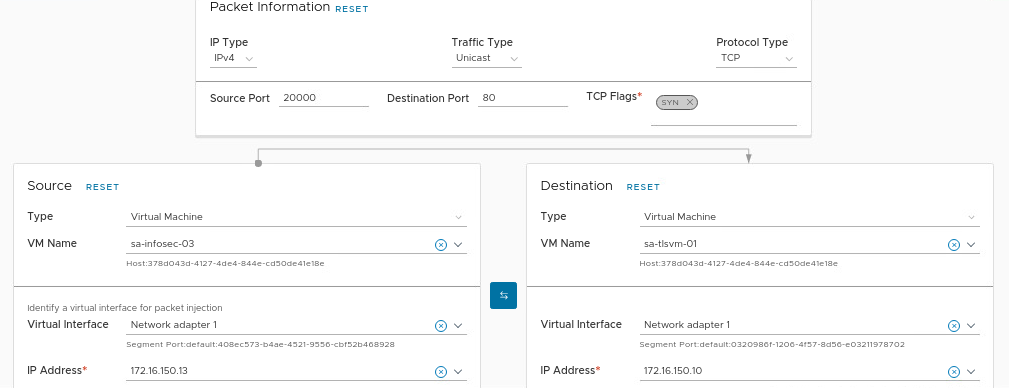
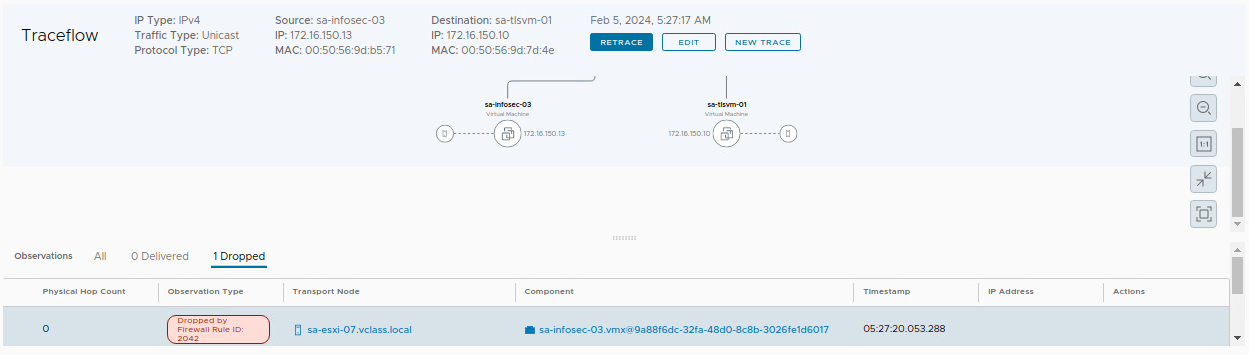
Here, we can conclude that we do not have an East-West rule to allow this traffic. So, we need to check all East-West rules again carefully. Let’s do that!
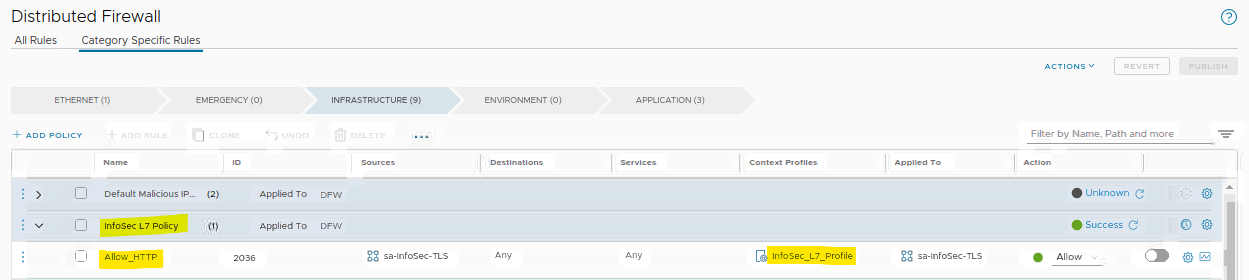
Under the distributed firewall rules, we found an interesting policy “InfoSec L7 Policy”. Under this policy we have a rule “Allow_HTTP” with an applied context profile:
We will open this context profile just to see what configuration we have inside it:
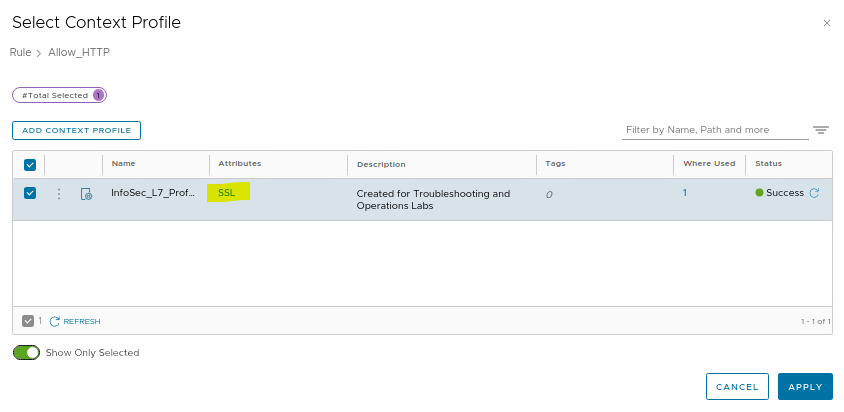
As we can see, we have an “SSL” attribute, however, our traffic is HTTP and does not use HTTPS (SSL). So, based on this, we will remove the “SSL” and add “HTTP”:
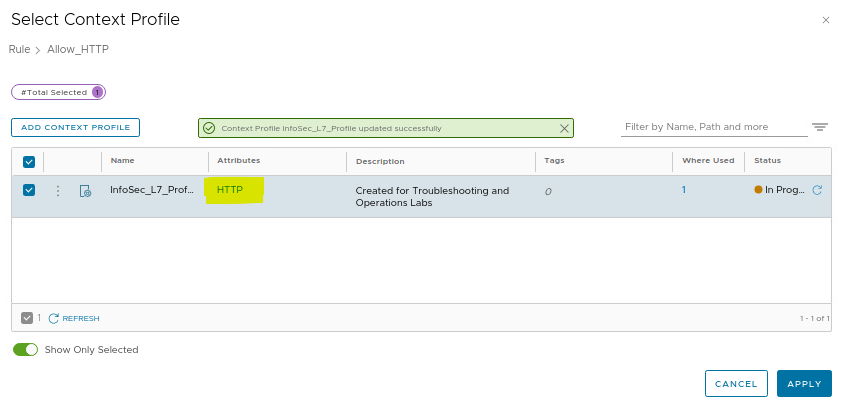
Note: The rule “Allow_HTTP” was disabled. I enabled it!
From our source VM, test the curl command again:
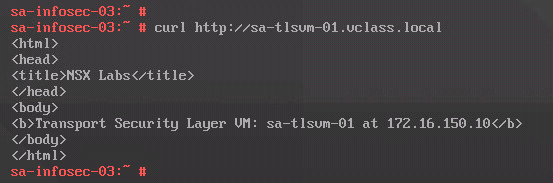
That’s it 🙂 We fixed the issue and the HTTP page was loaded successfully!
To Wrapping This Up
So, as we can see, there are a couple of ways to troubleshoot an issue in the NSX environment.
In my mind, I always try to reproduce the error or the issue (when possible). I believe there is an excellent way to have my vision or feeling of the issue.
And finally, always use the traceflow tool. This tool is the best way to understand what is happening with the packets from a source place to a destination place.