Replacing a Failed Disk on an SDS node shows all the necessary steps to replace a faulty disk on an SDS node part of a PowerFlex cluster.
Replacing failed disk devices is a common task for any storage administrator. Because of that, it is fundamental to understand what steps are necessary to replace a failed disk correctly. In this case, for instance, we are running a PowerFlex Cluster in a lab environment (PowerFlex Software-Only), and we will show how to replace a failed disk on an SDS node. Our lab was made based on Linux (SLES 15 SP4).
A rebuild job is initiated immediately when a disk failure occurs in the PowerFlex Cluster. This guarantees data redundancy and resilience. Another copy of the data will be reconstructed within another SDS node in the cluster!
Warning: All the steps that we'll show here were tested on a Lab envorinment. So, be careful if you are on a Production environment. We'll not be responsible for any error, downtime, or data loss in your Production environment!1- To replace a fault disk, the first step is to access the Primary MDM by SSH, log in to the MDM cluster, and check the SDS device status:
scli –login –management_system_ip pfmp.lab.local –username admin
scli –query_all_sdsAs we can see in the following picture, we have five SDS nodes, and all are “Connected”:

2- The next recommended step is to check the disk status of each SDS node. We can do it by executing the following command:
scli --query_sds --sds_name SDS01 | egrep -i "Path:|State:"In this example, the SDS named “SDS01” has three disk devices, and their status is “Normal” (it means each device is working fine):

Note: We can repeat the same command by replacing the SDS node name to check the disk status for the other SDSs:
scli --query_sds --sds_name SDS02 | egrep -i "Path:|State:“
scli --query_sds --sds_name SDS03 | egrep -i "Path:|State:“
scli --query_sds --sds_name SDS04 | egrep -i "Path:|State:“
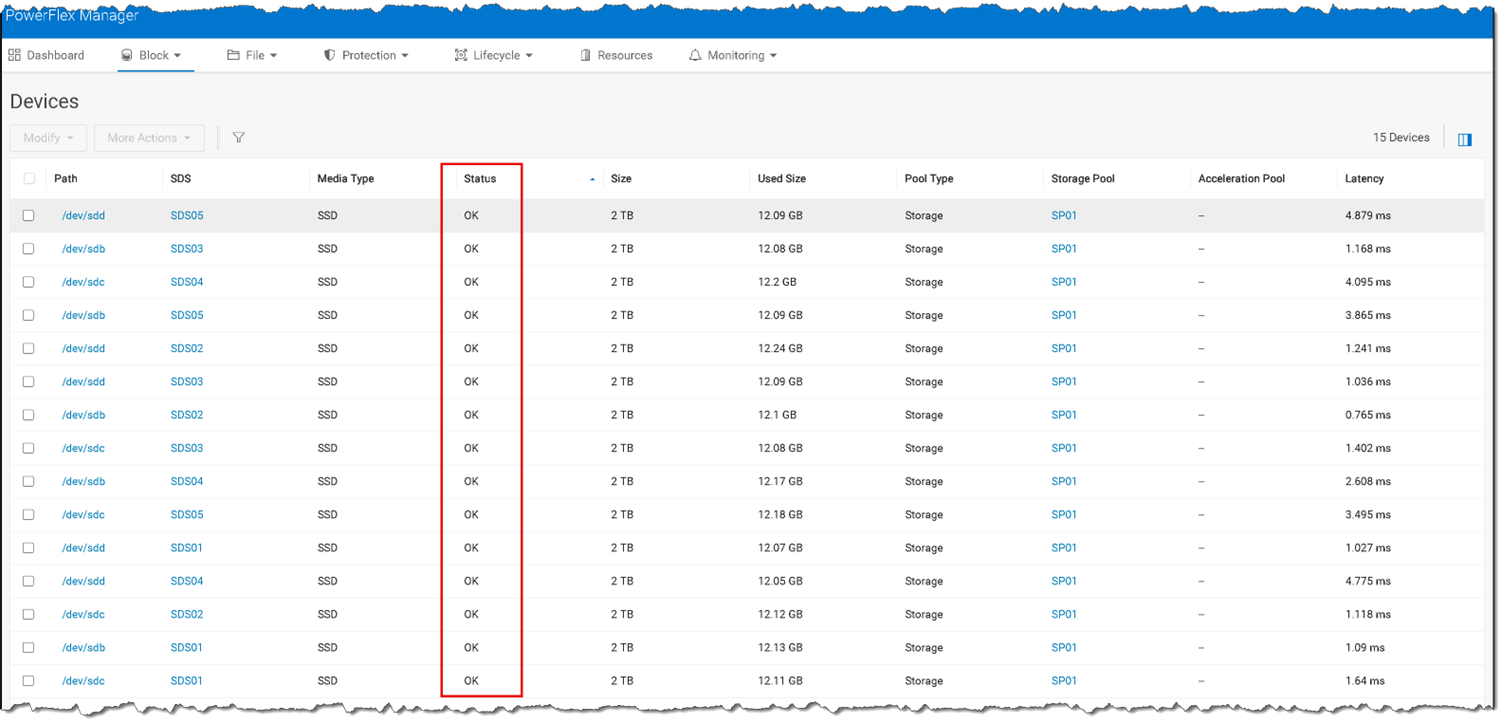
scli --query_sds --sds_name SDS05 | egrep -i "Path:|State:“3- Another way to check the status of the disks is through the PowerFlex Manager UI. Access the PowerFlex Manager UI à Block à Devices à Look at the “Status” column:
4- We will simulate a failure on a disk device of the SDS named “SDS02”. To check all physical disks on this SDS node and their status, follow the instructions below:
lsblk
ls -l /sys/block/sdb/device
cat /sys/block/sdb/device/state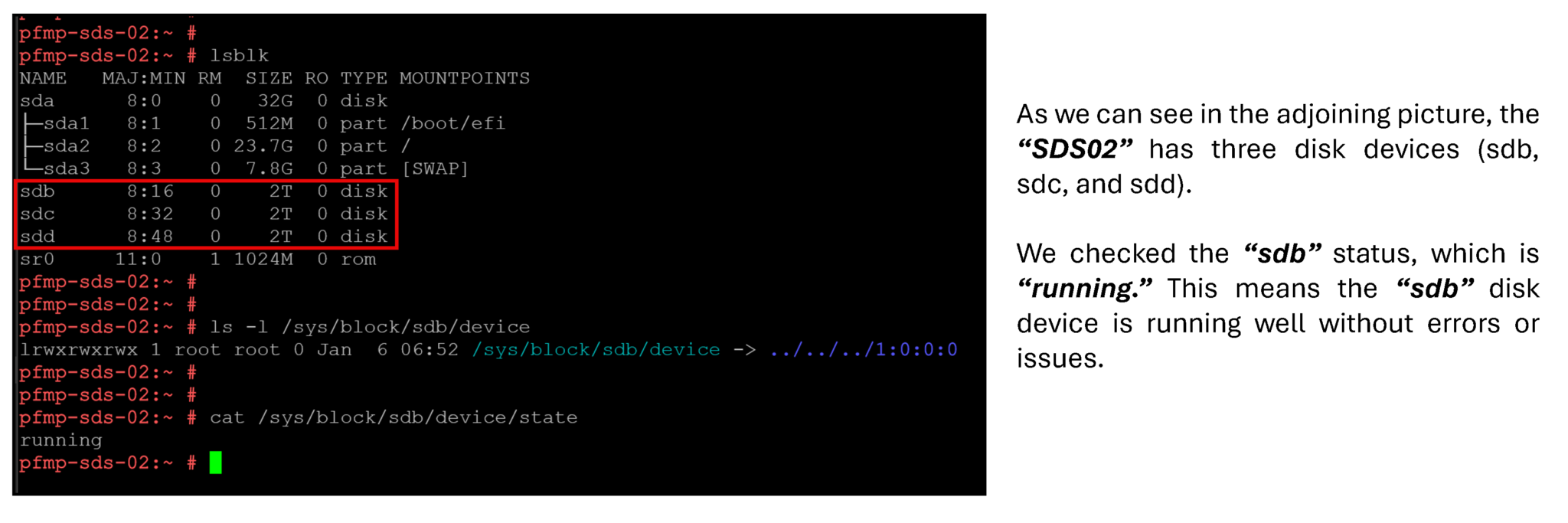
5- Simulate a disk failure on the “sdb” disk device:
echo "offline" > /sys/block/sdb/device/state
Go to the Primary MDM command line, log in, and check the “SDS02” disk devices. As we can see, the disk “sdb” has an “error” status:
scli --login --management_system_ip pfmp.lab.local --username admin
scli --query_sds --sds_name SDS02 | egrep -i "Path:|State:"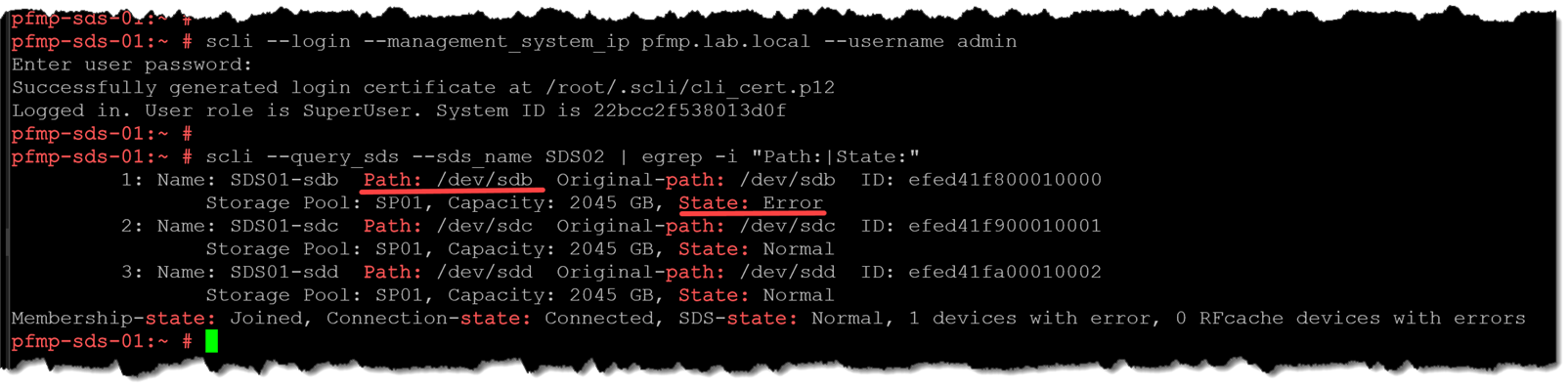
6- We can also confirm through the PowerFlex Manager UI that the disk “sdb” has an “error” status:
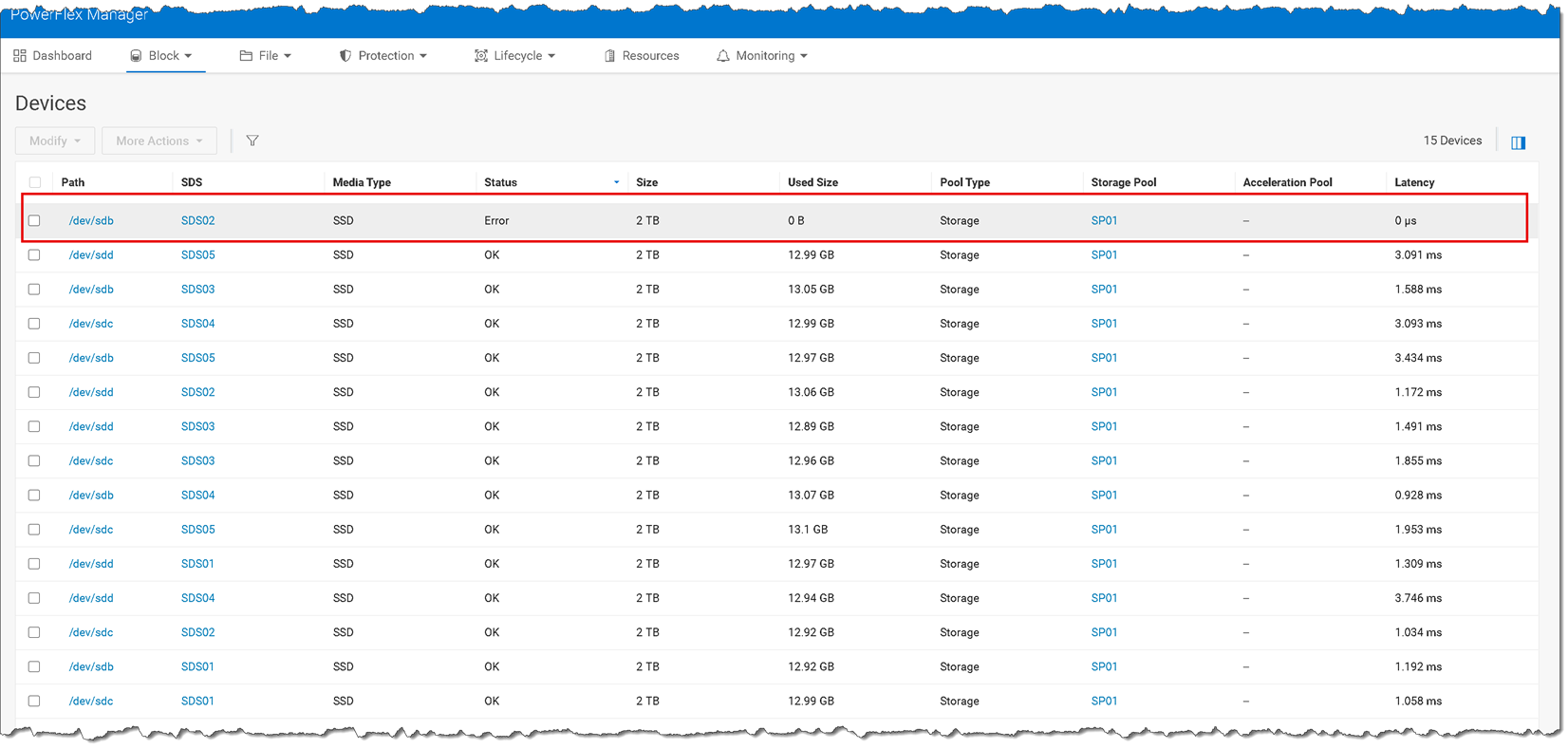
7- Under the Monitoring –> Alerts menu, we can see the disk failure alert as well:
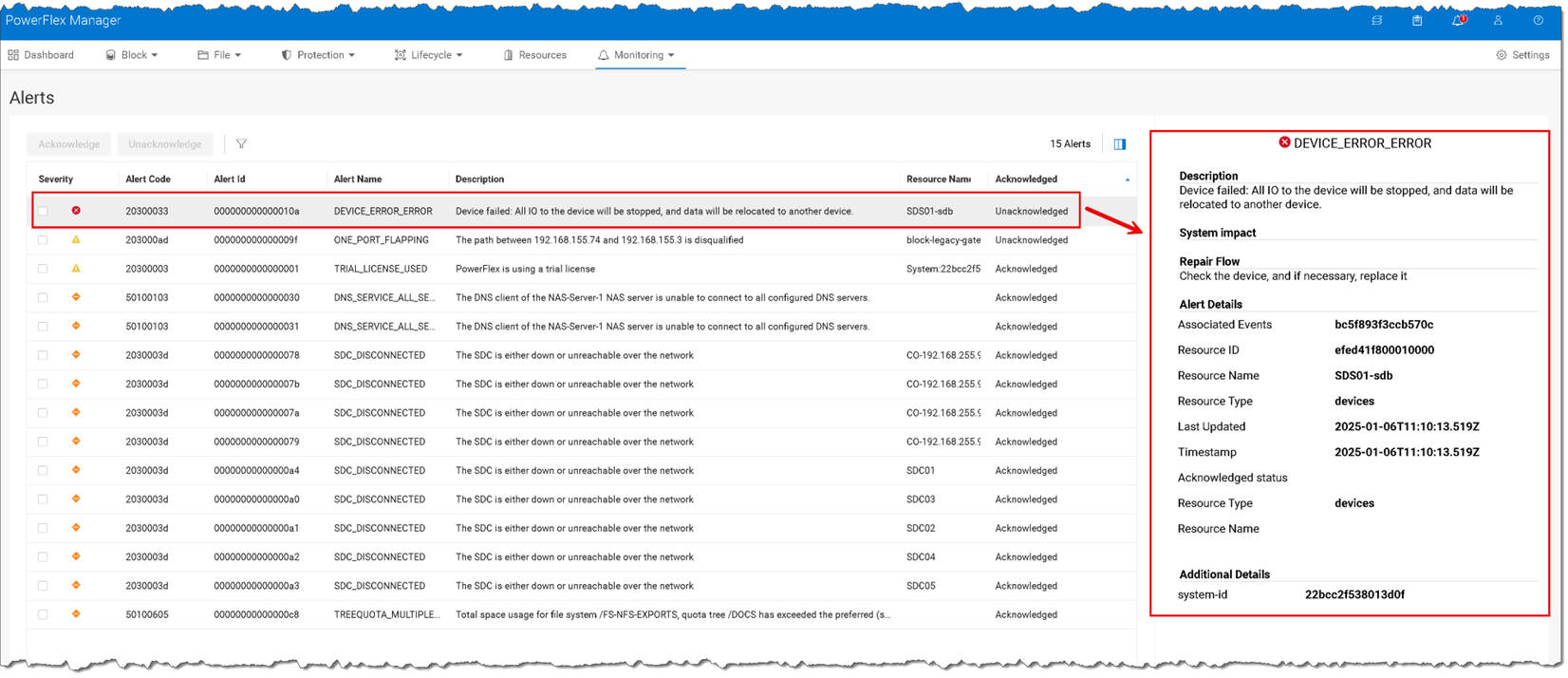
8- Remove the faulty device from the Storage Pool:
scli --login --management_system_ip pfmp.lab.local --username admin
scli --query_sds --sds_name SDS02 | egrep -i "Path:|State:“
scli --remove_sds_device --device_id efed41f800010000 --sds_name SDS02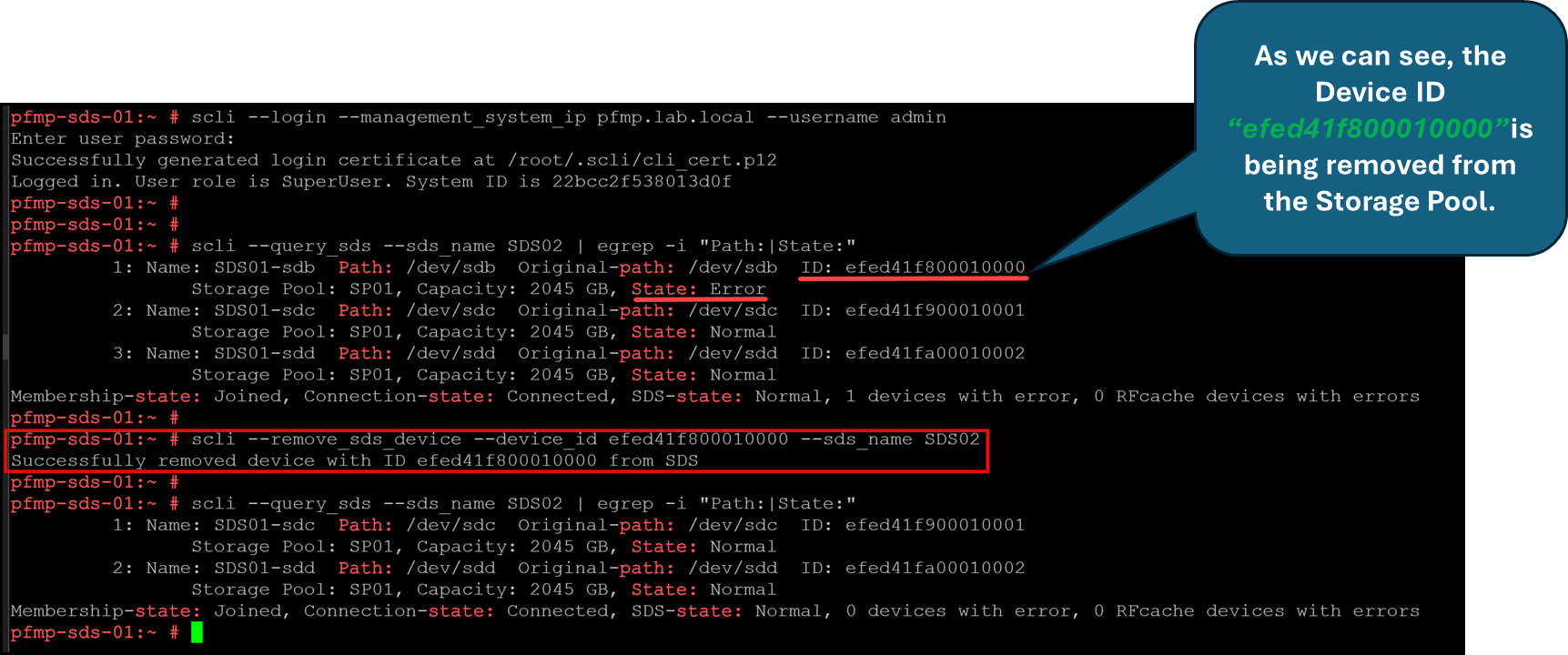
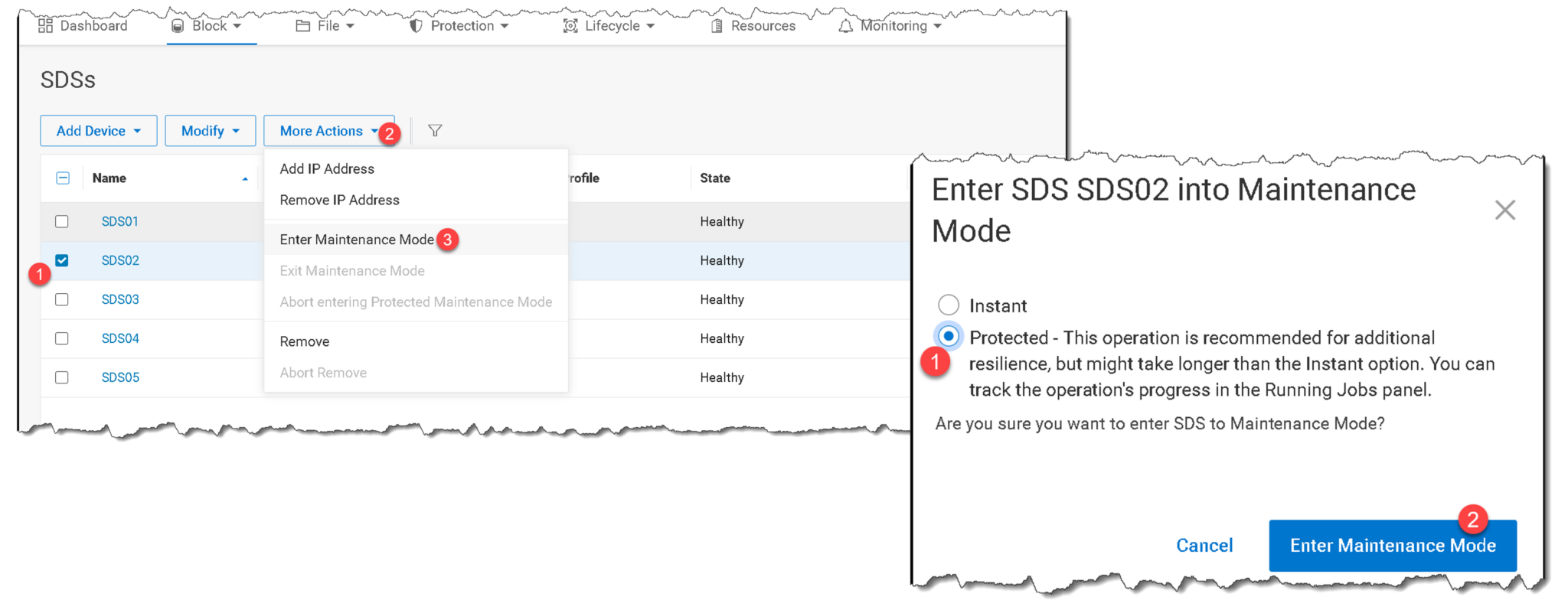
9- Replace the faulty disk device using the relevant system and vendor guidelines. If the disk is a “hot swap,” you do not need to shut the server down to replace it. However, if it is not a “hot swap,” you must put the node in maintenance mode and shut it down before replacing the faulty disk:
10- After physically replacing the faulty disk, add the new disk to the Storage Pool. In our case, the new disk was recognized as “/dev/sdd”:
scli --add_sds_device --sds_name SDS02 --device_path /dev/sdd --device_name SDS02-sdd --storage_pool_name SP01As we can see in the following picture, the new disk has been added successfully:

All disks for this SDS node are “Normal” (running fine):

Remove the SDS node from maintenance mode!
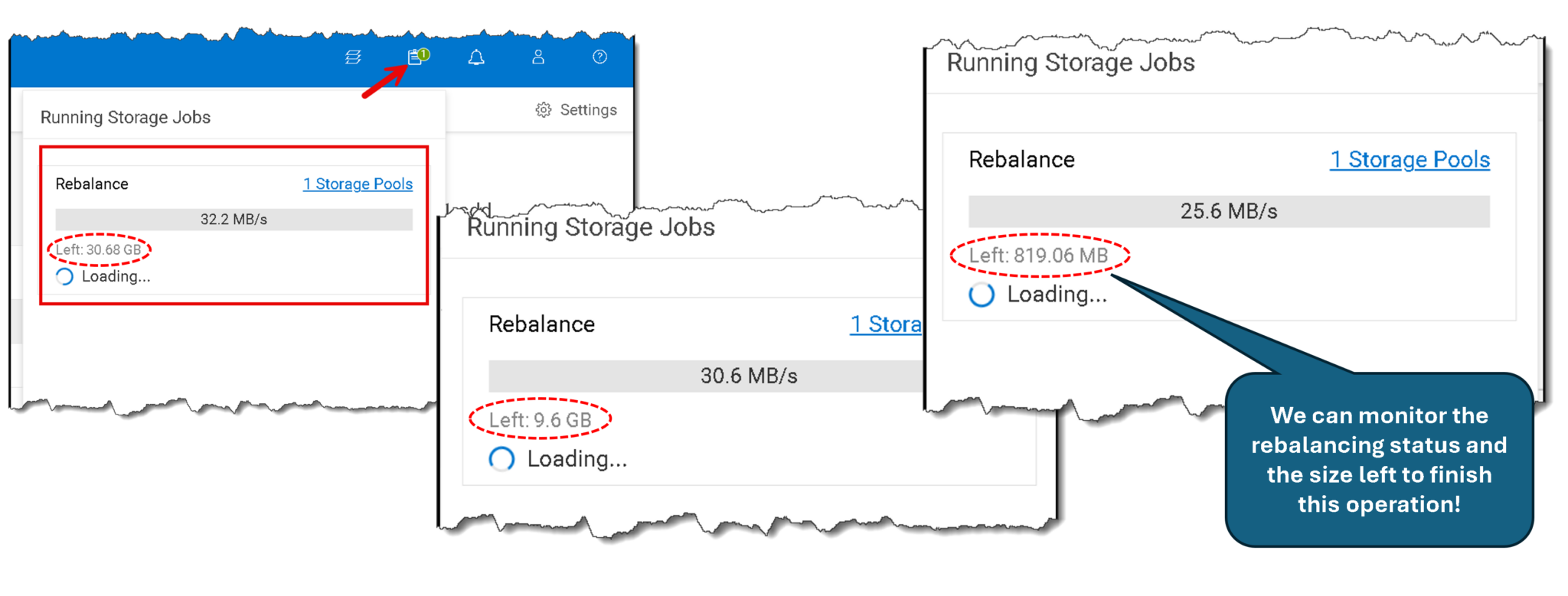
11- A rebalance job could start to rebalance the disk utilization within the Storage Pool. It is normal behavior since the newly added disk is empty (To remember, the PowerFlex monitors the utilization of every used disk. When it detects unbalancing disk utilization, a rebalance background job is started to fix it):
That’s it 🙂